
https://friendshipkim97.tistory.com/43
[Spring Batch] 공공데이터 OPEN API 활용시, 반복적으로 DB에 저장 자동화하기 - (1)
공공임대주택 공공데이터 API를 활용해 다음과 같은 화면을 구성해야 하는 일이 생겼습니다! 지역별로 쉐어하우스의 개수를 지도에 표시하는건데요, 이를 청년주택 데이터로 구마다 표시하려
friendshipkim97.tistory.com
저번 포스팅에서, Spring Batch의 필요성에 대해 알아봤습니다!
이번 포스팅에서는 Spring Batch를 실제로 공공데이터들에 활용해 보는 과정을 진행하겠습니다!
제가 사용한 공공데이터는 다음과 같습니다.
https://www.data.go.kr/tcs/dss/selectApiDataDetailView.do?publicDataPk=15058476
한국토지주택공사_공공임대주택 단지정보 조회 서비스
LH공사에서 관리하는 공공임대주택의 단지 정보 제공
www.data.go.kr
공공데이터를 살펴보니, 정말 많은 데이터가 있었습니다. 정확히는 아니지만 대략적으로 세봤을때 약.. 4만개 정도의 많은 데이터였습니다. 스프링 배치를 구성하기 위한 패키지구조는 다음과 같이 구성했습니다.

작업 스케쥴링 자바 라이브러리 quartz를 위한 scheduler패키지와 일괄처리 작업을 하는 Spring Batch 프레임워크를 위한 batch 패키지입니다.
batch 패키지안에는 batch 프로세스안에서 트랜잭션 단위인 chunk,
Open Api를 요청하기 위해 시군구 상수들을 모아놓은 constant,
요청받은 데이터를 db에 저장하기 위한 domain, dto,
하나의 배치작업 자체를 의미하는 job,
Spring MVC구조에서 볼 수 있는 repository, service
마지막으로 chunk기반의 정형화된 방식이 아니라, 자유로운 방식을 사용하기 위한 tasklet입니다.
그렇다면 이제부터 자세히 알아보겠습니다!

JobLauncher로 Job을 실행하는 메서드입니다! job의 id가 각각달라야 job 인스턴스가 만들어지기 때문에 해당 날짜의 타임을 id로 담았습니다. 즉, 반복해서 db의 데이터를 지우고 open Api를 받아와서 적재해야 하기 때문에 id를 다르게 한 것입니다!

Trigger를 이용해 새벽 4시마다 하나의 job을 실행하도록 설정했습니다.
쉽게 설명하자면 새벽 4시마다 하나의 openApiJob을 반복하도록 구현했고 openApiJob은 db의 공공임대주택 데이터를 모두 지우고, open Api를 요청해 db에 적재합니다.
Job의 전체적인 구조는 다음과 같습니다.


하나의 Job안에서 두 개의 Step이 실행됩니다. 첫번째로, 기존 db에 있던 데이터를 지우는 deleteDataStep, 두번째로 open Api를 요청해 db에 적재하는 openApiStep입니다.
그런데 각각의 스텝은 진행되는 방식이 다른데요, deleteDataStep은 tasklet방식으로, openApiStep은 reader, processor, writer방식으로 구현했습니다. 간단한 과정이면 tasklet을, 정형화된 방식이라면 후자의 방법을 택한 것이죠!
tasklet안에서는 간단히 db의 내용을 전부 지웠습니다

Spring Batch에서 주의할점은 끝나는 지점을 알려줘야 한다는 것입니다! 그렇지 않으면 무한루프에 빠질 수 있습니다. Tasklet에서는 RepeatStatus.FINISHED로 끝나는지점을 설정했습니다.

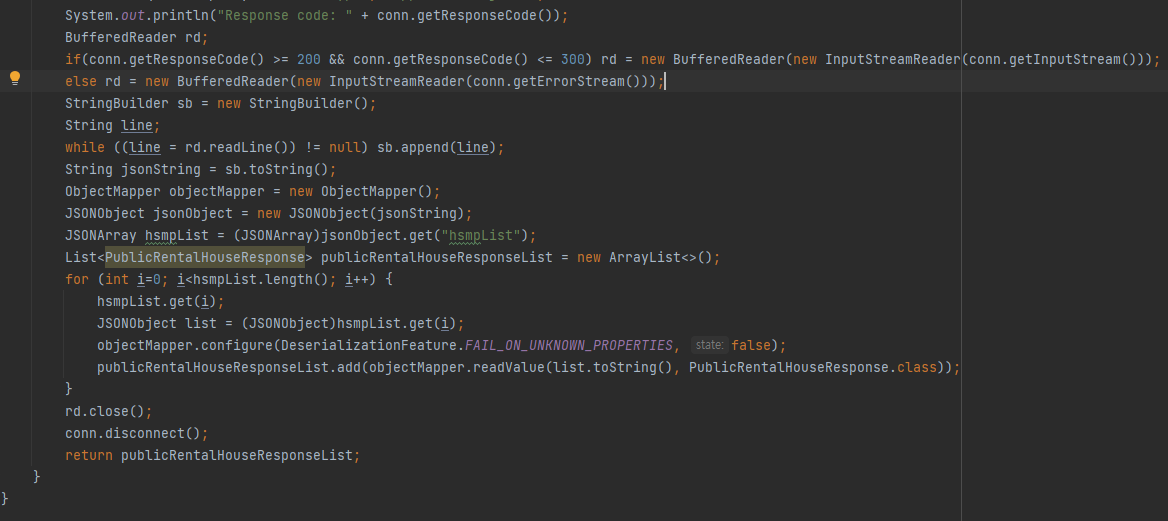
리팩토링을 안하다보니.. 코드가 너무 지저분한 것 같습니다! 이부분은 나중에 수정하도록 하겠습니다.
open Api를 요청하고 읽어들이는 과정입니다. count가 25면 null을 반환하도록 하였는데요 이를 설정하지 않으면 무한루프에 빠지게 됩니다. 25인 이유는, 다음과 같습니다.

서울특별시에 있는 시군구별로 요청을 하기 때문에 constant패키지에 저장해둔 시군구코드들을 다 부르고 25가 된다면 null을 반환해 파일의 끝이 어딘지 알려주는 것이죠!

프로세서는 다음과 같이 구성했습니다. ModelMapper를 이용하였는데, 이 과정에서 시간이 많이 소요됐습니다.
open Api에서는 JSON형식으로 들어올 때 객체가 빈 값이 들어온다면 {}과 같이 들어옵니다.

다음과 같이 빈 객체일때 competDe가 {}로 들어오는 것을 확인할 수 있습니다. 그런데, 이걸 다 일일히 파싱하다가 dto에서 어떻게 반환해야하는지 고민했습니다. {}라고 들어올 경우 String도 아니고 숫자도 아니라서 에러가 발생했습니다.
++ 추가적으로.. 공공데이터를 가져올 때 일일히 다 파싱하는 방법밖엔 없는지? 객체로 바로 받는 방법이 궁금해서 찾아봤는데 찾기 쉽지 않았습니다. 예를 들어 스프링+안드로이드 구조에서 안드로이드쪽에서는 레트로핏을 이용해 객체로 받는 것 처럼 말이죠! (이 부분은 많이 고민해봐야 할 것 같습니다.)
따라서, 필자는 Reader에서 일단 {}에러를 막기 위해 제너릭으로 받고 Processor에서 null로 처리했습니다.

다음과 같이 ModelMapper를 커스텀한 코드로 변환했습니다.
마지막으로 Writer는 다음과 같이 구성했습니다.


돌려보면, 워크벤치에 다음과 같이 데이터가 들어감을 확인할 수 있었습니다!
또한, 운영서버에도 매일 반복적으로 데이터가 들어가는지 체크해보면 다음과 같습니다!

매일 새벽 4시마다 반복되는 걸 확인할 수 있습니다.
사실 필자는 정말 필요한 기능들만 구현하는 것에 집중했지만, 따지고보면 문제점들이 정말 많음을 확인할 수 있습니다.
++Spring Batch는 멀티스레드를 이용해 처리하는 기능들도 존재하고, 깊게 알아야 사용할 수 있는 기능들이 많기 때문에 이를 활용하지 못한점이 아쉬웠습니다!
++또 새벽4시마다 Job이 실행될때 필자의 노트북 기준으로 6만개의 데이터를 지우는데 2분정도가 소요되는데, 운영서버는 사양이 낮아 더 오래 걸릴 것 같습니다. 따라서, 이 시간동안 사용자가 들어온다면 데이터가 없게 되는데 어떻게 대처해야 할지도 고려해야할 부분인 것 같습니다!
++또한, 스프링배치를 따로 서버를 둬서 메인서버와 통신하는게 더 바람직한 구조인지..? 고려해야할 부분이라고 생각했습니다!
스프링배치.. 맛보기정도로만 사용해서 하는데도 시간이 정말 오래걸렸습니다! 하지만, Spring Batch의 큰 틀에 대해서는 이해했고 조금 더 세부적으로 알아갈 때 분명 많은 도움이 될 거라 확신합니다!
